Train FCN on Pascal VOC Dataset¶
This is a semantic segmentation tutorial using Gluon Vison, a step-by-step example. The readers should have basic knowledge of deep learning and should be familiar with Gluon API. New users may first go through A 60-minute Gluon Crash Course.
Start Training Now¶
Please follow the installation guide to install MXNet and GluonVision if not yet. Use the quick script to Prepare Pascal VOC Dataset.
Clone the code:
git clone https://github.com/dmlc/gluon-vision cd scipts/segmentation/
Example training command:
# First training on augmented set CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset pascal_aug --model fcn --backbone resnet50 --lr 0.001 --checkname mycheckpoint # Finetuning on original set CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset pascal_voc --model fcn --backbone resnet50 --lr 0.0001 --checkname mycheckpoint --resume runs/pascal_aug/fcn/mycheckpoint/checkpoint.params
For more training command options, please run
python train.py -hTable of pre-trained models, performances and training commands:
Dive into Deep¶
Fully Convolutional Network¶
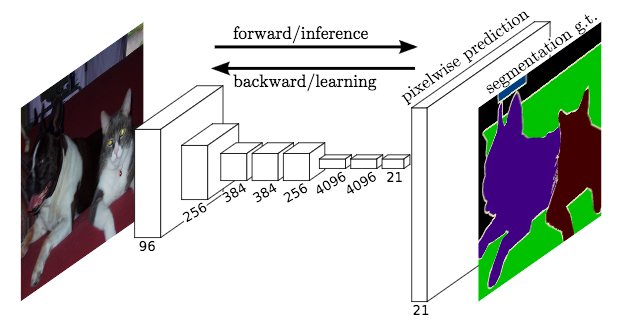
(figure redit to Long et al. )
State-of-the-art approaches of semantic segmentation are typically based on Fully Convolutional Network (FCN) [Long15] . The key idea of a fully convolutional network is that it is “fully convolutional”, which means it does have any fully connected layers. Therefore, the network can accept arbitrary input size and make dense per-pixel predictions. Base/Encoder network is typically pre-trained on ImageNet, because the features learned from diverse set of images contain rich contextual information, which can be beneficial for semantic segmentation.
Model Dilation¶
The adaption of base network pre-trained on ImageNet leads to loss spatial resolution,
because these networks are originally designed for classification task.
Following recent works in semantic segmentation, we apply dilation strategy to the
stage 3 and stage 4 of the pre-trained networks, which produces stride of 8
featuremaps (models are provided in gluonvision.model_zoo.Dilated_ResNetV2).
Visualization of dilated/atrous convoution:
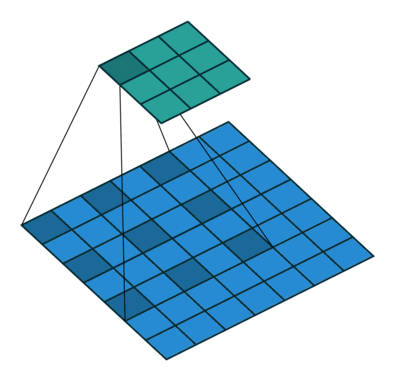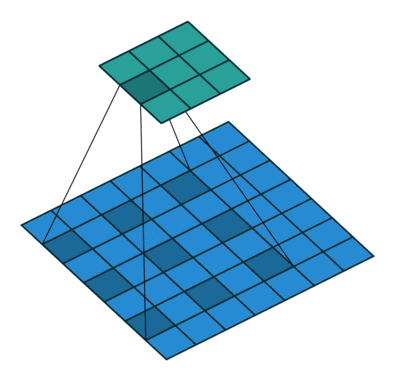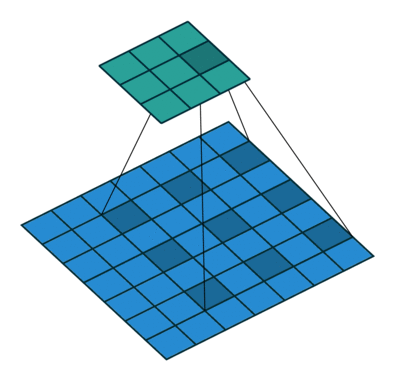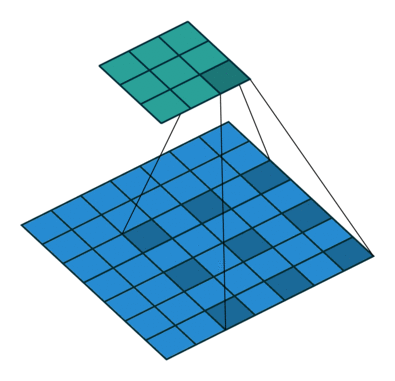
(figure credit to conv_arithmetic )
For example, loading a dilated ResNet50 is simply:
pretrained_net = gluonvision.model_zoo.dilated_resnet50(pretrained=True)
For convenience, we provide a base model for semantic segmentation, which automatically
load the pre-trained dilated ResNet gluonvision.model_zoo.SegBaseModel, which can
be easily inherited and used.
FCN Block¶
We build a fully convolutional “head” on top of the basenetwork (FCN model is provided
in gluonvision.model_zoo.FCN):
class _FCNHead(HybridBlock):
def __init__(self, nclass, norm_layer):
super(_FCNHead, self).__init__()
with self.name_scope():
self.block = nn.HybridSequential(prefix='')
self.block.add(norm_layer(in_channels=2048))
self.block.add(nn.Activation('relu'))
self.block.add(nn.Conv2D(in_channels=2048, channels=512,
kernel_size=3, padding=1))
self.block.add(norm_layer(in_channels=512))
self.block.add(nn.Activation('relu'))
self.block.add(nn.Dropout(0.1))
self.block.add(nn.Conv2D(in_channels=512, channels=nclass,
kernel_size=1))
def hybrid_forward(self, F, x):
return self.block(x)
class FCN(SegBaseModel):
def __init__(self, nclass, backbone='resnet50', norm_layer=nn.BatchNorm):
super(FCN, self).__init__(backbone, norm_layer)
self._prefix = ''
with self.name_scope():
self.head = _FCNHead(nclass, norm_layer=norm_layer)
self.head.initialize(init=init.Xavier())
def forward(self, x):
_, _, H, W = x.shape
x = self.pretrained(x)
x = self.head(x)
x = F.contrib.BilinearResize2D(x, height=H, width=W)
return x
Dataset and Data Augmentation¶
We provide semantic segmentation datasets in gluonvision.data.
For example, we can easily get the Pascal VOC 2012 dataset:
train_set = gluonvision.data.VOCSegmentation(root)
We follow the standard data augmentation routine to transform the input image and the ground truth label map synchronously. (Note that “nearest” mode upsample are applied to the label maps to avoid messing up the boundaries.) We first randomly scale the input image from 0.5 to 2.0 times, then rotate the image from -10 to 10 degrees, and crop the image with padding if needed.
References¶
| [Long15] | Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. |
import numpy as np
from tqdm import tqdm
import mxnet as mx
from mxnet import gluon, autograd
import gluonvision.utils as utils
from gluonvision.model_zoo.segbase import SegEvalModel
from gluonvision.utils.parallel import ModelDataParallel
from option import Options
from utils import save_checkpoint, get_data_loader, get_model_criterion
class Trainer(object):
def __init__(self, args):
self.args = args
self.net, self.criterion = get_model_criterion(args)
if args.test:
self.test_data = get_data_loader(args)
else:
self.train_data, self.eval_data = get_data_loader(args)
self.lr_scheduler = utils.PolyLRScheduler(args.lr, niters=len(self.train_data),
nepochs=args.epochs)
kv = mx.kv.create(args.kvstore)
self.optimizer = gluon.Trainer(self.net.module.collect_params(), 'sgd',
{'lr_scheduler': self.lr_scheduler,
'wd':args.weight_decay,
'momentum': args.momentum,
'multi_precision': True},
kvstore = kv)
self.evaluator = ModelDataParallel(SegEvalModel(self.net.module, args.bg), args.ctx)
def training(self, epoch):
tbar = tqdm(self.train_data)
train_loss = 0.0
for i, (data, target) in enumerate(tbar):
self.lr_scheduler.update(i, epoch)
with autograd.record(True):
outputs = self.net(data)
losses = self.criterion(outputs, target)
mx.nd.waitall()
autograd.backward(losses)
self.optimizer.step(self.args.batch_size)
for loss in losses:
train_loss += loss.asnumpy()[0] / self.args.batch_size * len(losses)
tbar.set_description('Epoch %d, training loss %.3f'%\
(epoch, train_loss/(i+1)))
mx.nd.waitall()
# save every epoch
save_checkpoint(self.net.module, self.args, False)
def validation(self, epoch):
total_inter, total_union, total_correct, total_label = 0, 0, 0, 0
tbar = tqdm(self.eval_data)
for i, (data, target) in enumerate(tbar):
outputs = self.evaluator(data, target)
for (correct, labeled, inter, union) in outputs:
total_correct += correct
total_label += labeled
total_inter += inter
total_union += union
pixAcc = 1.0 * total_correct / (np.spacing(1) + total_label)
IoU = 1.0 * total_inter / (np.spacing(1) + total_union)
mIoU = IoU.mean()
tbar.set_description('Epoch %d, validation pixAcc: %.3f, mIoU: %.3f'%\
(epoch, pixAcc, mIoU))
mx.nd.waitall()
def main(args):
trainer = Trainer(args)
if args.eval:
print('Evaluating model: ', args.resume)
trainer.validation(args.start_epoch)
else:
print('Starting Epoch:', args.start_epoch)
print('Total Epoches:', args.epochs)
for epoch in range(args.start_epoch, args.epochs):
trainer.training(epoch)
trainer.validation(epoch)
if __name__ == "__main__":
args = Options().parse()
main(args)